 大数据
大数据 软件测试
软件测试 Java开发
Java开发 Web前端开发
Web前端开发 全域电商运营
全域电商运营 全链路UI/UE设计
全链路UI/UE设计 VR/AR游戏开发
VR/AR游戏开发 Python+人工智能
Python+人工智能 新媒体与短视频运营
新媒体与短视频运营










-
 视频有效期
视频有效期
-
 课程内容
课程内容
-
 录播时长
录播时长
-
 直播有效期
直播有效期
-
 面授集训
面授集训
立即咨询
随到随学 7天内可申请退费



 精心研发
精心研发 


 课程老旧
课程老旧 录播不限次回看
录播不限次回看







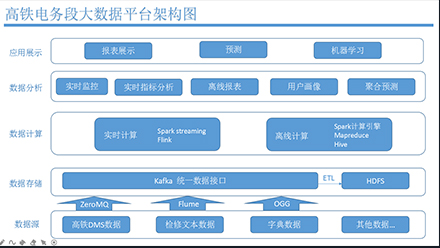



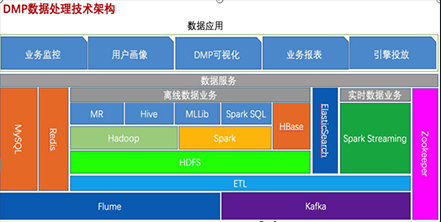


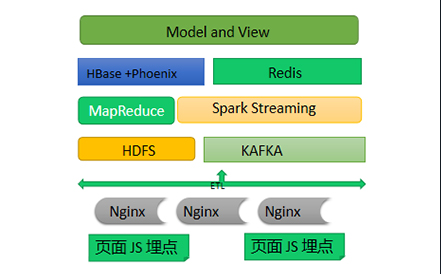


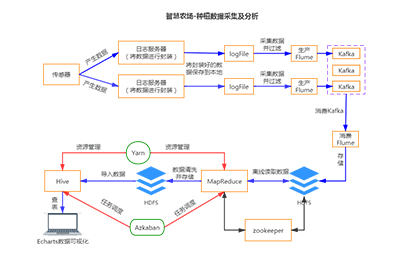
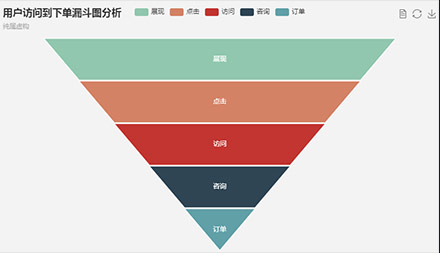

 第一阶段:Java基础
第一阶段:Java基础 第二阶段:JavaEE核心
第二阶段:JavaEE核心


























 视频支持离线缓存,终身有效
视频支持离线缓存,终身有效